Чи варто блокувати GPTBot від OpenAI на своєму сайті та як це зробити?

Amazon, Quora, New York Times, CNN уже заблокували веб-краулер GPTBot й обмежили тим самим доступ OpenAI до їхнього контенту.
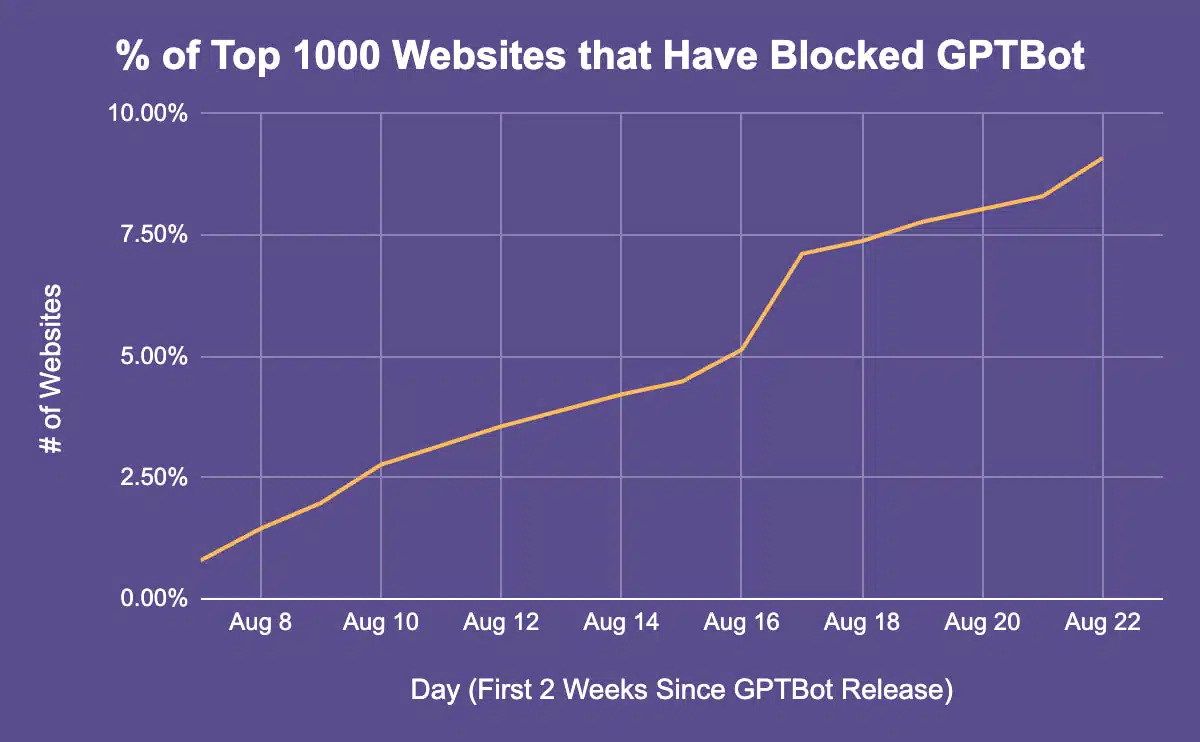
Нове дослідження від Originality.ai виявило, що станом на 29 серпня вже щонайменше 12% з 1000 найпопулярніших вебсайтів у світі заблокували GPTBot, новий веб-сканер OpenAI, представлений 7 серпня. І відсоток цей щодня зростає.
Серед сайтів, які вже блокують бота:
- amazon.com
- quora.com
- nytimes.com
- wikihow.com
- cnn.com
- ikea.com
- coursera.org
Чому це відбувається?
Тексти і зображення в Інтернеті технічно захищено авторським правом. Однак пошукові роботи на кшталт GPTBot не запитують дозволу чи ліцензії і зазвичай не платять за використання будь-яких даних або інформації, які видобувають з сайтів. Також ChatGPT не цитує і не посилається на свої джерела.
Відповідно сайти, які занепокоєні використанням свого матеріалу для навчання ШІ, намагаються убезпечити свій контент, заблокувавши GPTBot в robots.txt.
Та варто памʼятати, що крім GPTBot є ще й веб-сканер CCbot (від Common Crawl). Частина навчальних даних, які використовують OpenAI, Google та інші, надходить саме від нього.
New York Times, наприклад, заблокував обидвох ботів.
Чи варто блокувати GPTBot на своєму сайті?
Кілька думок про те, чому не варто бігти поперед батька в пекло й блокувати GPTBot.
Системи ШІ про вас нічого не знатимуть. Зараз люди із задоволенням користуються ChatGPT для пошуку певних товарів. І хоча бот скаже вам, що як штучний інтелект не має права чогось радити, список компаній на ваш запит “Де купити хостинг в Україні” він таки видасть.
Відповідно, якщо ви заблокуєте ботам ШІ доступ до вашого сайту, то створите дефіцит знань про вас, і в підсумку не потрапите у список згаданих ШІ брендів. Цей приклад досить спрощений, бо іноді такі історії набувають прямо-таки глобальних масштабів – якщо правдивої інформації про ваш товар в базах даних немає, значить її можна легко замінити дезінформацією.
А зважаючи на те, що нейромережі навчаються з кожним новим запитом, подібні “хибні поради” будуть множитися, а репутація вашого продукту страждати.
А тепер розглянемо зворотний бік медалі – поговорімо, в яких випадках вам таки варто заблокувати GPTBot:
- якщо ви заробляєте кошти на інформації – наприклад, представляєте інформаційне агентство чи видаєте художню літературу;
- якщо люди використовують штучний інтелект як заміну вашому основному продукту. Наприклад, ви маєте SEO-агентство, а люди консультуються з ChatGPT для досліджень ключових слів. Такий сценарій стосується практично всієї сфери консультативних послуг, коли ШІ фактично діє як прямий конкурент;
- якщо ви стурбовані тим, що інформація, захищена авторським правом, розміщується невідповідною, без вказівки автора і поза контекстом може бути сприйнята неправильно. Це стосується більше особистих блогів;
- якщо ваша організація має етичні заперечення щодо використання ШІ – актуально, наприклад, для сайту спілки письменників, акторів чи інших митців;
- якщо ви монополіст у своїй сфері / очевидно випереджаєте конкурентів й спокійно пануєте на вершині рейтингу Google, то для вас, можливо, немає сенсу віддавати свій трафік ChatGPT.
Як заборонити GPTBot сканувати ваш сайт?
Хоча запізно щось робити з уже зісканованими даними, ви все одно можете зупинити навчання моделей на вашому поточному та майбутньому контенті. І все, що для цього потрібно, це два рядки коду в robots.txt, як прописано в документації самої OpenAI.
Файл robots.txt розташований у кореневій папці вашого сайту за адресою www.yoursite.com/robots.txt/. Він містить правила, які визначають, чи можуть певні боти сканувати ваш сайт.
Щоб заборонити GPTBot доступ до вашого сайту, ви можете додати GPTBot до файлу robots.txt:
User-agent: GPTBot
Disallow: /Зауважимо, що ви можете заборонити ШІ-моделям використовувати не весь ваш контент, а лише певну його частину. Наприклад, ви не проти, щоб ваша головна сторінка була використана, однак якимось бізнес-кейсом ділитися не бажаєте. Щоб дозволити GPTBot доступ лише до певних частин вашого сайту, ви можете додати токен GPTBot до файлу robots.txt вашого сайту:
User-agent: GPTBot
Allow: /directory-1/
Disallow: /directory-2/Як дізнатися, чи сайт вже сканували для навчання ШІ?
OpenAI, як відомо, не розголошує інформацію про те, на яких сайтах навчався GPT-4. З міркувань конкуренції OpenAI заявила, що не буде ділитися деталями “архітектури (включно з розміром моделі), апаратного забезпечення, навчальних обчислень, побудови набору даних, методу навчання тощо”.
Коротше кажучи, немає ніякого способу дізнатися, сканувався сайт GPTBot-ом чи ні. Тому все, що ви можете зробити, це вжити перерахованих вище заходів, якщо не хочете, щоб дані вашого сайту використовувалися для навчання ШІ-моделі.
На завершення
Тепер ви маєте більш чітке уявлення про те, що відбувається у світі штучного інтелекту, який щодня дедалі глибше інтегрується в наше життя. А щодо блокування GPTBot, приймайте виважене рішення, яке буде безпосередньо відповідати інтересам вашої організації чи компанії.
Якщо ви все ж вирішили заборонити OpenAI сканувати частину або весь ваш сайт, зробити це, як бачите, дуже просто, всього два рядки коду в robots.txt і вуаля.
Сподобалася стаття? Поділіться нею з друзями.
Можливо, вас зацікавить

Сучасний цифровий ландшафт змінився – вже, певне, й не залишилося вебмайстрів, яких хоч трохи...

Навколо створення контенту зі штучним інтелектом багато галасу і захоплення, але й крихти скептицизму...

Хоча в програмуванні уже виділився цілий напрямок, повʼязаний із розробкою штучного інтелекту, самих інструментів,...
Наш телеграм
з важливими анонсами, розіграшами й мемами
Приєднатися