Стоит ли блокировать GPTBot от OpenAI на своем сайте и как это сделать?

Amazon, Quora, New York Times, CNN уже заблокировали веб-краулер GPTBot и ограничили тем самым доступ OpenAI к их контенту.
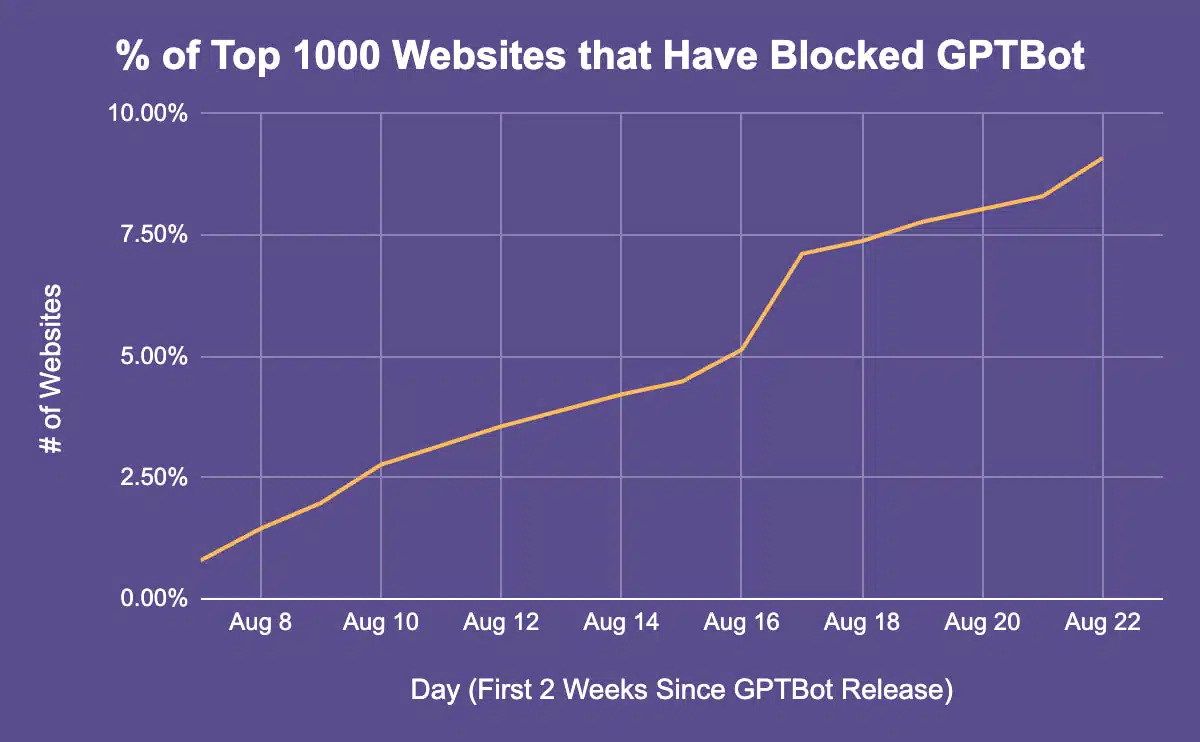
Согласно с новым исследованием от Originality.ai, по состоянию на 29 августа уже по меньшей мере 12% из 1000 самых популярных веб-сайтов в мире заблокировали GPTBot, новый веб-сканер OpenAI, представленный 7 августа. И процент этот ежедневно растет.
Среди сайтов, которые уже блокируют бота:
- amazon.com
- quora.com
- nytimes.com
- wikihow.com
- cnn.com
- ikea.com
- coursera.org
Почему это происходит?
Тексты и изображения в Интернете технически защищены авторским правом. Однако поисковые роботы вроде GPTBot не запрашивают разрешения или лицензии и обычно не платят за использование каких-либо данных или информации, которые добывают с сайтов. Также ChatGPT не цитирует и не ссылается на свои источники.
Соответственно сайты, которые обеспокоены использованием своего материала для обучения ИИ, пытаются обезопасить свой контент, заблокировав GPTBot в robots.txt.
Но стоит помнить, что кроме GPTBot есть еще и веб-сканер CCbot (от Common Crawl). Часть учебных данных, которые используют OpenAI, Google и другие, поступает именно от него.
New York Times, например, заблокировал обоих ботов.
Стоит ли блокировать GPTBot на своем сайте?
Несколько мыслей о том, почему не стоит бежать впереди паровоза и блокировать GPTBot.
Системам ИИ о вас ничего не будет известно. Сейчас люди с удовольствием пользуются ChatGPT для поиска определенных товаров. И хотя бот скажет вам, что как искусственный интеллект не имеет права чего-то советовать, список компаний на ваш запрос «Где купить хостинг в Украине» он все же выдаст.
Соответственно, если вы заблокируете ботам ИИ доступ к вашему сайту, то создадите дефицит знаний о вас, и в итоге не попадете в список упомянутых ИИ брендов. Этот пример довольно упрощенный, потому что иногда такие истории приобретают прямо-таки глобальные масштабы – если правдивой информации о вашем товаре в базах данных нет, значит ее можно легко заменить дезинформацией.
А учитывая то, что нейросети обучаются с каждым новым запросом, подобные «ложные советы» будут множиться, а репутация вашего продукта страдать.
А теперь рассмотрим обратную сторону медали – давайте поговорим, в каких случаях все же стоит заблокировать GPTBot:
- если вы зарабатываете на информации – например, представляете информационное агентство или издаете художественную литературу;
- если люди используют искусственный интеллект как замену вашему основному продукту. Например, у вас есть SEO-агентство, а люди консультируются с ChatGPT для исследования ключевых слов. Такой сценарий касается практически всей сферы консультативных услуг, когда ИИ фактически действует как прямой конкурент;
- если вы обеспокоены тем, что информация, защищенная авторским правом, размещается несоответствующей, без указания автора и вне контекста может быть воспринята неправильно. Это касается больше личных блогов;
- если ваша организация имеет этические возражения относительно использования ИИ – актуально, например, для сайта союза писателей, актеров или других художников;
- если вы монополист в своей сфере / очевидно опережаете конкурентов и спокойно господствуете на вершине рейтинга Google, то для вас, возможно, нет смысла отдавать свой трафик ChatGPT.
Как запретить GPTBot сканировать ваш сайт?
Хотя поздно что-то делать с уже отсканированными данными, вы все равно можете остановить обучение моделей на вашем текущем и будущем контенте. И все, что для этого нужно, это две строчки кода в robots.txt, как прописано в документации самой OpenAI.
Файл robots.txt расположен в корневой папке вашего сайта по адресу www.yoursite.com/robots.txt/. Он содержит правила, которые определяют, могут ли определенные боты сканировать ваш сайт.
Чтобы запретить GPTBot доступ к вашему сайту, вы можете добавить GPTBot в файл robots.txt:
User-agent: GPTBot
Disallow: /Заметим, что вы можете запретить ИИ-моделям использовать не весь ваш контент, а только определенную его часть. Например, вы не против, чтобы ваша главная страница была использована, однако каким-то бизнес-кейсом делиться не желаете. Чтобы разрешить GPTBot доступ только к определенным частям вашего сайта, вы можете добавить токен GPTBot в файл robots.txt вашего сайта:
User-agent: GPTBot
Allow: /directory-1/
Disallow: /directory-2/Как узнать, сканировался ли ваш сайт для обучения ИИ?
OpenAI, как известно, не разглашает информацию о том, на каких сайтах обучался GPT-4. Из соображений конкуренции OpenAI заявила, что не будет делиться деталями «архитектуры (включая размер модели), аппаратного обеспечения, учебных вычислений, построения набора данных, метода обучения и т.д.».
Короче говоря, нет никакого способа узнать, сканировался сайт GPTBot-ом или нет. Поэтому все, что вы можете сделать, это принять вышеперечисленные меры, если не хотите, чтобы данные вашего сайта использовались для обучения ИИ-модели.
В завершение
Теперь вы имеете более четкое представление о том, что происходит в мире искусственного интеллекта, который с каждым днем все глубже интегрируется в нашу жизнь. А что касается блокировки GPTBot, принимайте взвешенное решение, которое будет непосредственно соответствовать интересам вашей организации или компании.
Если вы все же решили запретить OpenAI сканировать часть или весь ваш сайт, сделать это, как видите, очень просто, всего две строчки кода в robots.txt и вуаля.
Понравилась статья? Поделитесь ею с друзьями.
Возможно, вас заинтересует

Современный цифровой ландшафт изменился – уже, наверное, и не осталось вебмастеров, которых хоть немного...

Вокруг создания контента с искусственным интеллектом много шума и восторга, но и нотки скептицизма...

Хотя в программировании уже выделилось целое направление, связанное с разработкой искусственного интеллекта, самих инструментов,...
Наш телеграм
с важными анонсами, розыгрышами и мемами
Присоединиться